커리어 스터디
도메인과 직무를 기반으로 커리어 분석
내가 선택한 도메인과 직무에 대해 추가적으로 학습합니다.
- 주요 제품과 공정 과정, 분석 기법 등
- 주요 업무와 필수 역량, 채용 공고 등
그간의 조사 결과를 바탕으로 커리어 분석 결과를 정리합니다.
직무 : QC
도메인 : 철강
필수 역량
- 제품의 품질 유지, 향상
- 꼼꼼함, 분석력, 품질 표준 및 규정 이해
- 데이터 분석 및 문제 해결 능력
- 의사소통 및 협업능력
- 신속성과 유연성
- 지속적인 개선과 학습
주요 업무
- 품질 보증 및 관리 업무, 품질경영시스템 인증 업무, 품질 이슈 대응 및 품질 개선 업무
- 부품 품질 관리, 완제품 품질 관리
- 제품의 양산성 확보, 품질 향상을 위한 제조 공정 및 설비 개조/관리, 제품의 불량분석과 품질 최적화
- 품질 검사 및 테스트, 공정 품질관리, 결함 분석 및 개선, 표준 준수 및 인증 관리, 고객 및 클레임 관리, 품질 데이터 분석 및 보고, 장비 및 설비 관리
- 생산성과 고객의 신뢰를 유지하기 위한 업무
주요 제품 : 코일, 강판, 형강, 봉강, 파이프, 특수강 등
철강 생산 공정
제철 : 고로(BF : Blast Furnace)에 철광석, 코크스를 넣고 녹여 선철(Pig iron)을 만듦
주요 데이터 : 고로 내부 온도, 철광석과 코크스 및 첨가제의 함유량, 비율 등
제강
1) 선철을 전로(BOF : Basic Oxygen Furnace)로 옮기고 산소를 불어넣어 불순물 제거하는 정련 공정. 불순물이 제거된 용강 만듦
2) 철 스크랩을 전기로(EAF : Electric Ark Furnace)에 넣어 용강을 만듦
주요 데이터 : 전로, 전기로 내부 온도, 전로에 주입된 산소량 등
주조 : 주형틀(Mold)에 용강을 부어 반제품 형태로 굳힘(슬래브, 블룸, 빌렛, 주괴)
주요 데이터 : 냉각 속도, 균열, 슬래그 혼입 정도, 미세조직, 반제품의 길이 및 형상 데이터 등
압연 : 열간/냉간 압연 등의 성형 공정을 통해 반제품을 최종 철강 제품 제작
주요 데이터 : 온도, 속도, 제품 두께와 폭의 균일한 정도, 기계적 특성, 결함 여부 등

실시간 공정 모니터링을 통해 공정이 안정적으로 유지될 수 있도록 조절
머신러닝, AI 모델을 사용하여 공정 데이터 분석을 통한 최적 공정 조건 도출
공정 중 파악이 어려운 주조 과정 등의 내부 상태를 시뮬레이션을 사용하여 시각화
데이터 분석을 통해 표면 결함, 기계적 특성 저하, 크랙 발생 등의 원인을 파악하여 방지할 수 있도록 조치
공정 데이터, 설비 데이터를 기반으로 장비의 이상 신호를 사전에 감지하여 고장 예방
즉, 공정 개선, 품질 향상, 비용 절감, 설비 유지보수, 환경 관리 등 모든 측면에서 사용됨
진행 시험
인장 시험
경도 시험
충격 시험
굽힘 시험
예시
포스코 인공지능 기반 도금량 제어자동화 솔루션
- 자동차강판 생산의 핵심기술인 용융아연도금(CGL : Continuous Galvanizing Line)을 인공지능을 통해 정밀하게 제어함으로써 도금량 편차를 획기적으로 줄임
- 인공지능 기법의 도금량 예측모델과 최적화 기법의 제어모델이 결합되어 실시간으로 도금량을 예측하고 목표 도금량을 정확히 맞추는 자동제어 기술
- 고가의 아연이 불가피하게 많이 소모되었던 도금공정을 인공지능에 의해 자동으로 제어함으로써 자동차용 도금강판의 품질향상과 더불어 과도금량 감소로 인한 생산 원가 절감
- 자동운전으로 인한 작업자 부하도 경감시켜 작업 능률 및 생산성 향상
POSCO의 스마트 팩토리
수주공정
- 수작업하던 소Lot 주문을 AI가 예측하고 판단하여 공정 소요시간이 12시간에서 1시간으로 대폭 축소
- 주문에 영향을 주는 인자 12개를 도출하여 AI가 스스로 주문을 판단하는 학습모델 구축
- 설계 사이즈 예측으로 원가 낭비 없이 최적으로 제작
제선공정
- 작업자가 수작업으로 진행한 조업을 IoT 센서와 카메라 이미지를 통해 배출 형상을 데이터화
- 쇳물 온도를 IoT가 데이터화, 카메라를 통한 원료의 상태 자동 확인
- 1시간 후 상태까지 예측 관리하여 쇳물 생산량 증가
제강공정
- 용선의 온도와 성분, 원료가 달라도 조건에 맞게 AI 학습
- 경우의 수 12만 5천개 분석하는 전로~연주 연속 제어 시스템(PTX : Posco sTeelmaking eXpress) 개발
- 공정별 도착시간, 온도, 성분 실시간 확인으로 온도 적중률 90% 이상, 원료 사용량 60% 감소
연주공정
- 품질 이상에 대한 기준을 AI에 학습시켜 결함이 있는 소재만 선별 및 원인분석
- 기존에는 대표 소재만 100% 의무 검사 실행 후 이상 발생시 모든 소재 결함 분석
- 실적 데이터 자동 수집, 표면 품질 예측 모델 개발하여 불량재 발생시 자동 알림
- 불필요한 검사 없어지고 연간 6억원 원가 절감
압연공정
- 열간/냉간 평탄도 인자 데이터화, 빅데이터로 분석, 후판TMCP 학습모델 개발
- 평탄도 조건의 상관관계 분석으로 프로그램이 자동으로 최적의 TMCP 조건 생성
- 후 교정률 50% 저감 및 연간 13억원 절감
도금공정
- 딥러닝을 이용하여 목표 도금량 스스로 학습하여 정확하게 제어
- 도금 제어 적중률 89%에서 99%이상으로 향상
[출처] 철강산업에서 스마트팩토리 적용 현황 및 발전 방안, 한국철강협회
ANN 모델 : 철강 제조 공정에서 입력변수(HMRT, HTSZ, ORRT, SCH)와 출력변수(철강 생산량) 간의 관계를 높은 정확도로 예측
- HMRT(용선율), HTSZ(열크기), ORRT(철광석 투입률), SCH(고철 투입량)는 철강 생산량에 가장 높은 영향을 미치는 요소들
- Levenberg-Marquardt 알고리즘 사용

데이터 분석 종합반 4주차
데이터 분석 1강
직접 가설을 세우고 검증하기
게임종합반 구매전환률을 높여라!

데이터 분석 2강
데이터 전처리
광고 효율이 나지 않는 매체를 찾아라!
가설 세우기 : 여러 광고 매체 중 광고 효율이 낮은 매체에 사용한 비용을 가장 효율이 좋은 매체에 집행한다면 기존 대비 50%의 광고효율을 증대시킬 수 있을 것이다.(모든 광고 매체에 같은 비용을 쓰고 있다고 가정)
데이터 분석 3강
시각화 및 결론 도출

#

***결론***
옥외광고 비율을 줄이고, 광고 효율이 좋은 인스타그램, 페이스북 그리고 네이버 블로그 관련 홍보에 예산을 집중하자.
데이터 분석 4강
그래프 시각화

* 각 바마다 색 입히기
#
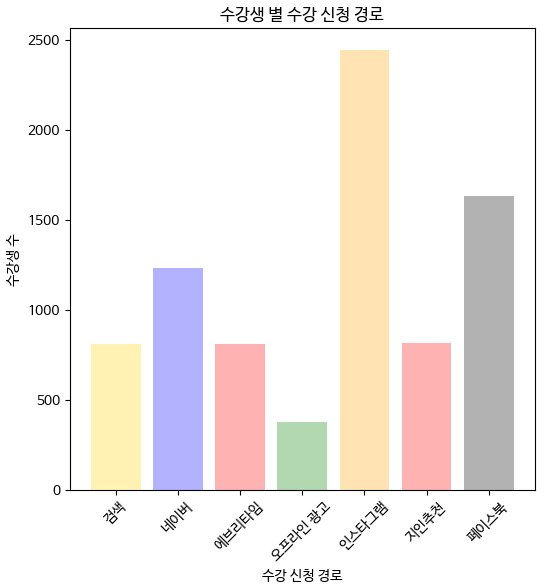
* 테두리 색 및 두께 변경

* 바 두께 변경하기(기본 값 = 0.8)

* 그래프 폰트 변경하기
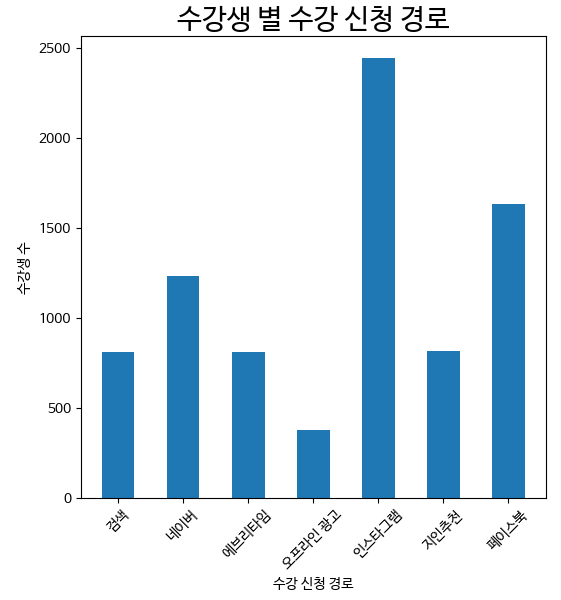
* 각 바의 수치 나타내기

* 가로 그래프 그리기

데이터 분석 5강
패키지 상품 기획하기_ 가설 수립 및 전처리
문제 파악 : 현재 게임개발 종합반이 다른 패키지에 포함되어 있는 강의들보다 구매 전환율이 저조한 상황입니다
추가 정보 : 이전의 웹개발 종합반과 엑셀보다 쉬운 SQL의 패키지 상품을 기획하여 기존 대비 각각 40%의 구매 전환율이 높아진 사례가 있습니다
원하는 결과 : 매력적인 패키지 상품을 기획하여 게임개발 종합반의 구매 전환율을 더욱 높이고자합니다.
가설 : 게임개발 종합반 과목을 산 인원 중 가장 많은 인원이 동시에 구입한 과목과 패키지를 기획해 판매한다면 약 30%의 구매 전환율을 높일 수 있을 것이다.

sum_of_students_by_class = sparta_data[sparta_data==1].count()


***결론***
게임 종합반에 가장 관심이 많았던 고객은, 앱개발 종합반 수강생이다.
추가 분석이 필요하다.
데이터 분석 6강
패키지 상품 기획하기_ 추가 가설 시각화 하기
왜 앱개발 종합반 신청자가 게임종합반에 관심이 많은 것인가?
가설 : 앱 종합반과 게임 종합반 신청자의 공통 관심사는 중 가장 큰 비율을 차지하는 것은 부수입 창출일 것이다.


#

***결론***
앱 개발, 그리고 게임 종합반 신청자의 공통 관심사는 부수입 창출이다.
데이터 분석 7강
할인은 정말 효과적인 선택일까?_ 전처리하기
문제 파악 :
결제 마지막 페이지에서 이탈률이 높은 상황입니다.
확인 해 본 결과, 결제 페이지 오류는 없는 상황입니다.
금액이 고객들의 구매 결정에 걸림돌이 되는 것으로 예상됩니다.
원하는 결과 :
결제 마지막 페이지에서 고객 이탈율을 줄이고 싶습니다.
가설: 결제 마지막 페이지에서 할인 쿠폰을 제공하여 금액적으로 구매 결정에 걸림돌을 제거해준다면 결제율을 높일수 있을 것이다.
같은 기간동안 선착순으로 결제 페이지에 접속한 각 12000명을 대상으로
첫번째 그룹 마지막 페이지 결제 접속자 에게 마지막 결제 페이지에 할인 쿠폰을 제공
두번째 그룹 마지막 페이지 결제 접속자 에게 할인 쿠폰 미 제공(정가 구매 유도)

데이터 분석 8강
할인은 정말 효과적인 선택일까? _ 데이터 분석 및 시각화
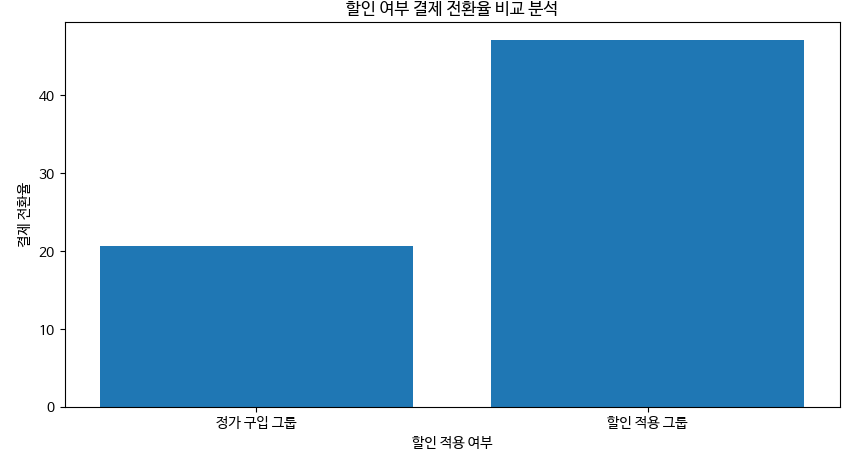
***결론***
할인 적용 신청 그룹의 신청율이 46% 대 20%로 정가 구입 그룹 보다 월등히 높다
고객의 구매 장벽을 낮추기 위해 마지막 페이지에 적절한 할인을 제시하는 것이 신규 수강생 모집에 효과적으로 보인다.
데이터 분석 9강
4주차 과제 제출(https://essay2892.tistory.com/16)
데이터 분석 5주차
데이터 분석 1강
💡 김르탄 팀장 🧑🏻💻:
“스파르타코딩클럽에서 수강 완주율은
좋은 컨텐츠 제공 여부 및 수강생 관리가 잘 되어 가고 있는지에 대한 가장 중요한 지표 입니다.
그런데 지난 8월 중순 부터 웹개발 종합반의 완주율이 크게 떨어졌습니다.”
이번 주는 무엇이 수강생들의 완주율에 가장 큰 영향을 미쳤는지 함께 고민 해 보고 개선해 봅시다.
❗ 8월 중순부터 완주율이 크게 떨어졌습니다. 이유를 찾아서 개선해봅시다!
데이터 분석 2강
데이터 분석 시작하기
가설을 세우기 이전에 어떤 변수가 있을지 파악 : 고객의 입장에서 수업을 듣는 여정 생각 해보기
[수강 여정]
- 강의를 들을 수 있는 시간적 여유가 생긴다.
- 강의를 들어야겠다고 마음을 먹는다.
- 강의를 듣기 위해 콘텐츠에 접근한다.
- 콘텐츠를 2에서 목표한 부분까지 듣는다.
1, 2, 4번이 각각 문제가 있지는 않을지 확인해보면 어떤 것이 완주를 가로막고 있을지에 대해 파악할 수 있습니다.
📌 이번주에는 1, 2, 4번을 살펴보면서 어떤 점을 개선하면 완주율을 높일 수 있을지
가설을 세워 확인하는 시간을 가져보겠습니다 :)

데이터 분석 3강
우리는 적절한 타겟에게 판매를 하고 있을까?
✔️ 시간이 없어 듣지 못하는 고객의 경우 저희가 무언가를 개선한다고 완주를 할 수 없습니다.
애초에 만족할 수 없는 고객에게 판매를 한 것이니 장기적 관점에서 포지셔닝 변경이 필요합니다.
⇒ 스파르타코딩클럽 정말로 포지셔닝 변경이 필요할지 데이터로 살펴봅시다!
가설 : 다른 연령대에 비해 바쁜 20~30대의 수강 완주율이 상대적으로 낮을 것이다.
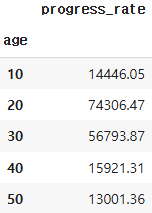



***결론***
2-30대의 완주율 평균이 다른 나이대와 비슷한 비율이라는 점을 확인
프로덕트 개선이나 광고 메인 타겟을 변경 등은 고려에서 배제해도 좋을 것이다.
데이터 분석 4강
찐한관리를 하면 완주율이 높아질까?_ 가설 및 전처리
가설 : 찐한관리를 받은 인원이 그렇지 않은 인원보다 완주율이 높을 것이다.
데이터 분석 5강
찐한관리를 하면 완주율이 높아질까? _ 분석 및 시각화


***결론***
찐한 관리를 받지 않은 그룹의 수강 완주율은 38.6%
찐한 관리를 받은 그룹의 수강 완주율은 68.5 %
찐한관리를 받은 그룹의 완주율이 월등히 높은 것을 확인
찐한관리 신청 비율을 높이는 액션을 진행해보는 것이 완주율 개선에 효과적일 것 같다.
수업 시작 전, 찐한관리 참여를 적극적으로 유도해보아도 좋을 것이다.
데이터 분석 6강
프로덕트 개선은 정말 도움이 되었을까?_ 가설 세우기
✔️ 목표한 만큼 강의 컨텐츠를 모두 수강 완료하는 것에 도움을 주려면
콘텐츠가 충분히 흥미있고 유익해야 합니다. 이 부분을 확인해볼까요?
→ 앗 이미 8월 즈음 콘텐츠 개편이 완료되어 적용된 상황입니다!
→ 흠.. 8월이라.. 완주율이 꺾인 시점과 유사한데 좀 더 파볼까요?
가설 : 8월 둘째 주 부터 변경된 3주 차 강의의 완주율이 현저히 떨어졌을 것이다.
2가지 요인이 복합적으로 작용하는 결과를 확인해야하므로 코호트 차트 만들기
데이터 분석 7강
프로덕트 개선은 정말 도움이 되었을까?_ 전처리 및 분석

Length: 1736
Categories (6, int64): [0 < 1 < 2 < 3 < 4 < 5]

#

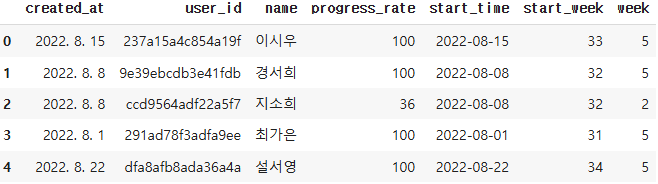


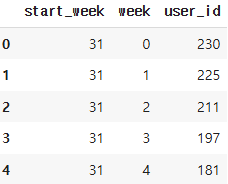
데이터 분석 8강
프로덕트 개선은 정말 도움이 되었을까_ 시각화





***결론***
4주 차 컬럼에서만 떨어진 것이 아니라 전체적으로 떨어진 것을 볼 수 있다.
다른 요인 때문에 완주율이 떨어졌다고 보는 것이 맞을 것 같다.
데이터 분석 9강
5주차 과제 제출(https://essay2892.tistory.com/17)
엑셀보다 쉽고 빠른 SQL 2주차
SQL 1강
복습 및 맛보기
SQL 2강
엑셀 대신 SQL로 한번에 계산하기 (SUM, AVERAGE, COUNT, MIN, MAX)
select food_preparation_time,
delivery_time,
food_preparation_time + delivery_time as total_time
from food_orders
select sum(food_preparation_time) total_food_preparation_time,
avg(delivery_time) avg_delivery_time
from food_orders
#

select avg(age) average_age
from customers
#

select count(1) count_of_orders,
count(distinct customer_id) count_of_customers
from food_orders
#

select count(*) as total_count,
count(distinct pay_type) as count_of_pay_type
from payments
#

select min(price) min_price,
max(price) max_price
from food_orders
#

SQL 3강
WHERE 절로 원하는 데이터를 뽑고, 계산해보기
주문 금액이 30,000원 이상인 주문건의 갯수 구하기
select count(*) as number_of_order
from food_orders
where price >= 30000
#

한국 음식의 주문 당 평균 음식가격 구하기
select avg(price)
from food_orders
where cuisine_type = 'Korean'
#

SQL 4강
GROUP BY로 범주별 연산 한 번에 끝내기
select cuisine_type,
sum(price) sum_of_price
from food_orders
group by cuisine_type
#

select restaurant_name,
max(price) max_price
from food_orders
group by restaurant_name
#

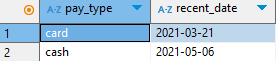
select pay_type,
max(date) recent_date
from payments
group by pay_type
#
SQL 5강
Query 결과를 정렬하여 업무에 바로 사용하기 (ORDER BY)
select cuisine_type,
sum(price) sum_of_price
from food_orders
group by cuisine_type
order by sum(price)
#

음식점별 주문 금액 최댓값 조회하기 - 최댓값 기준으로 내림차순 정렬
select restaurant_name,
max(price) as max_price
from food_orders
group by restaurant_name
order by max(price) desc
#

고객을 이름 순으로 오름차순으로 정렬하기
select *
from customers
order by name
#

SQL 6강
SQL 구조 마스터 - WHERE, GROUP BY, ORDER BY 로 완성되는 SQL 구조
[퀴즈] 조회 할 데이터를 SQL 구조에 맞춰서 바꿔보기
1.
order by sum(delivery_time) desc
group by cuisine_type
where day_of_the_week=’Weekend’
from food_orders
select cuisine_type, sum(delivery_time) total_delivery_time
답
select cuisine_type, sum(delivery_time) total_delivery_time
from food_orders
where day_of_the_week=’Weekend’
group by cuisine_type
order by sum(delivery_time) desc
2.
where age between 20 and 40
select age, count(name) count_of_name
order by age
group by age
from customers
답
select age, count(name) count_of_name
from customers
where age between 20 and 40
group by age
order by age
SQL 2주차 숙제 제출(https://essay2892.tistory.com/19)
'TIL(Today I Learned)' 카테고리의 다른 글
| [2024/12/23]내일배움캠프 QA/QC 1기 - 6일차 (0) | 2024.12.23 |
|---|---|
| [2024/12/20]내일배움캠프 QA/QC 1기 - 5일차 (2) | 2024.12.20 |
| [2024/12/18]내일배움캠프 QA/QC 1기 - 3일차 (5) | 2024.12.18 |
| [2024/12/17]내일배움캠프 QA/QC 1기 - 2일차 (1) | 2024.12.17 |
| [2024/12/16]내일배움캠프 QA/QC 1기 - 1일차 (1) | 2024.12.16 |