커리어 스터디
조사한 공정을 바탕으로, 관련 데이터를 탐색합니다.
해당 공정에서 발생할 수 있는 문제를 구체적으로 정의합니다.
더보기
제철(제선)
인, 황 등의 불순물이 많으면 선철의 품질 저하
온도 불균형, 열풍 주입 불균형으로 생산성 저하
온도, 압력 데이터, 공기(열풍) 주입량 파악
제강
산소 주입량, 동작 시간에 따라 철의 산화 또는 탄소 함량 과다
냉각제 부족으로 온도 과다 상승으로 철 손실 발생
온도, 산소 주입량 파악
주조
용강의 주형 내부 유동속도차, 온도차, 용질원소 불균형으로 인해 수축, 균열 등 여러 결함이 발생.
주입 속도가 높으면 용강 계면 불안정으로 인한 슬래그 혼입이 발생
열 전달 불균형으로 인해 비정상 초기 응고조직이 형성되어 가스 기포가 포집
주형 내부의 용강의 유동, 온도 분포, 용강 주입 속도, 주조 속도 파악
압연
롤러의 마모나 균열으로 인해 제품 표면 결함 또는 불균일하여 기준에 맞지 않는 제품 생성
두께, 폭, 온도 데이터, 압연 속도 파악
데이터 활용 직무의 공통점과 차이점
더보기
Data Analyst, Data Scientist, Quality Control Engineer
세 직무 모두 데이터를 기반으로 문제를 정의하고 해결 방안을 제시
데이터를 분석하여 인사이트를 도출하거나 품질을 개선하는 데 활용
데이터 정제(Cleaning), 처리(Processing), 시각화(Visualization) 등의 과정을 공통적으로 수행
Excel, Python, R, SQL과 같은 데이터 분석 도구를 사용
데이터를 통해 특정 문제를 해결하거나 개선하려는 목표
통계적 방법론, 데이터 모델링 등을 사용하여 의사결정
더보기
Data Analyst
- 비즈니스 데이터 분석 및 문제를 정의하여 해결책을 제시하는데 집중
- Data cleaning, Analysis, visualization 주로 진행
- 데이터 분석, 정리, 이해에 초점
Data Scientist
- 데이터 분석 및 머신러닝을 통해 패턴 분석, 예측 모델 개발에 집중
- 머신러닝/AI 알고리즘 모델 개발, 비즈니스 질문에 대한 예측
- 미래에 대한 예측에 초점
QC 엔지니어
- 제품의 품질 기준을 보장하고 생산 공정의 문제를 예방하는 것에 집중
- 최적의 공정 조건 파악, 실시간 모니터링을 통한 공정 안정화, 고장 예방
- 공정 안정화에 초점
각 도메인에서 공정 데이터를 활용하는 공통점과 차이점
더보기
실시간 공정 모니터링을 통해 공정이 안정적으로 유지될 수 있도록 조절
머신러닝, AI 모델을 사용하여 공정 데이터 분석을 통한 최적 공정 조건 도출
공정 중 파악이 어려운 주조 과정 등의 내부 상태를 시뮬레이션을 사용하여 시각화
데이터 분석을 통해 표면 결함, 기계적 특성 저하, 크랙 발생 등의 원인을 파악하여 방지할 수 있도록 조치
공정 데이터, 설비 데이터를 기반으로 장비의 이상 신호를 사전에 감지하여 고장 예방
즉, 공정 개선, 품질 향상, 비용 절감, 설비 유지보수, 환경 관리 등 모든 측면에서 사용됨
포스코 인공지능 기반 도금량 제어자동화 솔루션 : 자동차강판 생산의 핵심기술인 용융아연도금(CGL, Continuous Galvanizing Line)을 인공지능을 통해 정밀하게 제어함으로써 도금량 편차를 획기적으로 줄일 수 있는 기술.
인공지능 기법의 도금량 예측모델과 최적화 기법의 제어모델이 결합되어 실시간으로 도금량을 예측하고 목표 도금량을 정확히 맞추는 자동제어 기술
고가의 아연이 불가피하게 많이 소모되었던 도금공정을 인공지능에 의해 자동으로 제어함으로써 자동차용 도금강판의 품질향상과 더불어 과도금량 감소로 인한 생산 원가를 절감
자동운전으로 인한 작업자 부하도 경감시켜 작업 능률 및 생산성 향상
ANN 모델 : 철강 제조 공정에서 입력변수(HMRT, HTSZ, ORRT, SCH)와 출력변수(철강 생산량) 간의 관계를 높은 정확도로 예측
- HMRT(용선율), HTSZ(열크기), ORRT(철광석 투입률), SCH(고철 투입량)는 철강 생산량에 가장 높은 영향을 미치는 요소들
- Levenberg-Marquardt 알고리즘 사용
 PosFrame은 하단의 아티클 스터디 실제 사례 확인
PosFrame은 하단의 아티클 스터디 실제 사례 확인
아티클 스터디
2회차(https://essay2892.tistory.com/13)
데이터 분석 3주차
데이터 분석 1강
실제 직장생활에서 발생할법한 상황들로 파이썬 데이터 분석 진행
[이야기 1] 최적의 타이밍에 완주를 독려하는 고객 관리 메세지를 보내볼까요?
💁🏻♀️ 스파르타코딩클럽에서는 모든 수강생들이 완주 하는 것을 중요하게 생각합니다.
완주를 위한 고객관리 메세지를 보낼 최적의 시간대를 찾고싶은데요, 수강생들의 접속 데이터를 살펴보면 무슨 요일, 시간대에 수강생들이 수업을 주로 듣는지가 나오겠군요!
→ 목표 : 수강생들이 가장 많이 혹은 가장 적게 듣는 시간과 요일을 데이터 분석으로 찾기
동기 부여를 위한 관리 메세지의 최적의 시간대를 찾아봅시다! :)
[이야기 2] 수강 수요가 많은 지역을 찾아볼까요?
💁🏻♀️ 수강 수요가 많은 지역을 안다면, 보다 효율적인 광고 집행이 가능할 것 같아요!
어디서 수강생이 많이 모이는지 보고 그 지역의 특징을 분석해보면 좋을 것 같네요!
우선은 수강 수요가 많은 지역을 찾아봅시다
→ 목표 : 가장 수강을 많이 하는 지역을 데이터분석으로 찾기
데이터 분석 2강
목표 : 수강생들이 가장 많이 혹은 가장 적게 듣는 시간과 요일을 데이터 분석으로 찾기
더보기
import pandas as pd
sparta_data = pd.read_table('access_detail.csv', sep = ',')
sparta_data.head()
#
 lecture_id (수강 강의 id) access_date (접속 시작 날짜 및 시간) user_id (유저 id)
lecture_id (수강 강의 id) access_date (접속 시작 날짜 및 시간) user_id (유저 id)
데이터 분석 3강
[미션 1] 가장 적절한 고객 관리 타이밍은? _ 분석 준비하기
"언제", "누가" 접속하는지가 중요 - lecture_id 불필요
access_date의 접속 날짜 불필요
더보기
print(type(sparta_data['access_date'][0])) # <class 'str'>
문자열이 아닌 날짜정보이므로 데이터 형태 변환
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format='mixed')
sparta_data.tail(5)
to_datetime() : 해당 열의 데이터를 날짜와 시간 데이터로 변경
#

print(type(sparta_data['access_date_time'][0])) # <class 'pandas._libs.tslibs.timestamps.Timestamp'>
sparta_data['access_date_time_weekday'] = sparta_data['access_date_time'].dt.day_name()
sparta_data.tail(5)
[날짜 컬럼].dt.day_name : 해당 날짜의 요일 알 수 있음
#

sparta_data['access_date_time_hour'] = sparta_data['access_date_time'].dt.hour
[날짜 컬럼].dt.hour : 해당 날짜의 시간값 가져옴
#

weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('access_date_time_weekday')['user_id'].count()
weekdata
groupby(’컬럼명’)를 사용하면데이터를 특정 기준으로 그룹화
#

hourdata = sparta_data.groupby('access_date_time_hour')['user_id'].count()
hourdata = hourdata.sort_index()
hourdata
sort_index() : 오름차순(ascending)
sort_index(ascending = False) : 내림차순
#
데이터 분석 4강
[미션 1] 가장 적절한 고객 관리 타이밍은?_ 분석 및 시각화
더보기
import matplotlib.pyplot as plt
import numpy as np
numpy : 데이터 연산을 빠르고 쉽게 할 수 있게 도와주는 라이브러리
#그래프 사이즈
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.bar(weekdata.index, weekdata)
#그래프 명
plt.title('요일별 수강 완료 수강생 수')
#그래프 x축 레이블
plt.xlabel('요일')
#그래프 y축 레이블
plt.ylabel('수강생(명)')
#x축 레이블을 90도로 변환
plt.xticks(rotation=90)
#그래프 출력
plt.show()
#

#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.plot(hourdata.index, hourdata)
#그래프 명
plt.title('시간별 수강 완료 사용자 수')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 표시 하기
plt.xticks(np.arange(24))
np.arange() : 괄호에 명시된 간격으로 배열을 생성
#그래프 출력
plt.show()
#
더보기
#피벗테이블 만들기
#values : 열에 들어 가는 부분
#index : 행에 들어가는 부분
#aggfunc : 데이터 축약시 사용할 함수
sparta_data_pivot_table = pd.pivot_table(sparta_data, values='user_id',
index=['access_date_time_weekday'],
columns=['access_date_time_hour'],
aggfunc="count").agg(weeks)
sparta_data_pivot_table
#

#그래프 사이즈 변경
plt.figure(figsize=(14,5))
#pcolor를 이용하여 heatmap 그리기
plt.pcolor(sparta_data_pivot_table)
#히트맵에서의 x축
plt.xticks(np.arange(0.5, len(sparta_data_pivot_table.columns), 1), sparta_data_pivot_table.columns)
#히트맵에서의 y축
plt.yticks(np.arange(0.5, len(sparta_data_pivot_table.index), 1), sparta_data_pivot_table.index)
#그래프 명
plt.title('요일별 종료 시간 히트맵')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('요일')
#plt.colorbar() 명령어를 추가하면 그래프 옆에 숫자별 색상값을 나타내는 컬러바를 보여 줍니다
plt.colorbar()
plt.show()
#
더보기
1. 새로운 코드에 다음 코드를 작성
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
2. 런타임 재시작
3. 다음 코드를 그래프 코드 사이에 붙여넣기
plt.rc('font', family='NanumBarunGothic')
*** 결론 ***
“화요일” 그리고 “일요일”에 수강이 많이 이뤄졌고, “금요일” 과 “수요일”에 수강 하는 인원이 가장 적었다.
18시대에 접속이 폭발적으로 많았고, 밤 21시쯤에 감소하는 추세를 보였다.
화요일 18시에 가장 많은 접속자가 있다는 것을 확인 하였다.
고객 관리 문자는 가장 수강을 많이 한 화요일, 일요일 저녁시간쯤에 독려 문자를, 가장 수강을 적게 한 금요일, 수요일 오전시간에 동기부여 문자를 보내보는 것이 좋을 것 같다.
데이터 분석 5강
[미션 2] 제품 수요가 많은 지역을 찾아라! _ 라인 그래프 그리기
목표 : 가장 수강을 많이 하는 지역을 데이터분석으로 찾기
더보기
import pandas as pd
sparta_data = pd.read_table('students_area_detail.csv',sep=',')
sparta_data.head()
#
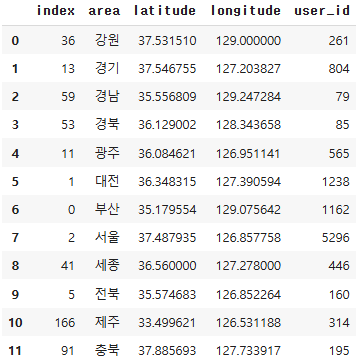
 lecture_id: 수강 강의 id area: 접속 지역 latitude: 해당 지역 위도 longitude: 해당 지역 경도 user_id: 유저 id
lecture_id: 수강 강의 id area: 접속 지역 latitude: 해당 지역 위도 longitude: 해당 지역 경도 user_id: 유저 id
category_range = set(sparta_data['area'])
print(category_range, len(category_range))
set() : 중복값 제거
# {'경남', '제주', '대전', '전북', '서울', '강원', '광주', '부산', '경북', '세종', '경기', '충북'} 12
필요한 데이터는 각 지역의 정보와 그 지역의 수강생 수
area_info=sparta_data[['area','latitude','longitude']]
area_info.head()
#

area_info=area_info.drop_duplicates(['area'])
area_info= area_info.reset_index()
area_info
#

area_info=area_info.drop_duplicates(['area'])
area_info = area_info.sort_values(by=["area"], ascending=[True])
area_info= area_info.reset_index()
area_info
#

number_of_students = pd.DataFrame(sparta_data.groupby('area')['user_id'].count())
number_of_students
#

result = pd.merge(area_info, number_of_students, on="area")
result
#
import matplotlib.pyplot as plt
import numpy as np
plt.rc('font', family='NanumBarunGothic')
#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.plot(result['area'], result['user_id'])
#그래프 명
plt.title('지역별 사용자 수')
#그래프 x축 레이블
plt.xlabel('지역')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 수
plt.xticks(np.arange(13))
#그래프 출력
plt.show()
#
데이터 분석 6강
[미션 2] 제품 수요가 많은 지역을 찾아라! _ 지도에서 한 눈에 보기
한걸음 더! 데이터를 실제 지도에 표시해서 살펴 볼까요~?
더보기
import folium
from folium.plugins import MarkerCluster
Folium : 분석한 데이터의 결과를 지도에 그리기 위한 라이브러리
MarkerCluster : 가까운 거리의 marker들을 군집시켜 해당 건수를 표현
m = folium.Map(location=[37.5536067,126.9674308],
zoom_start=11)
m
#
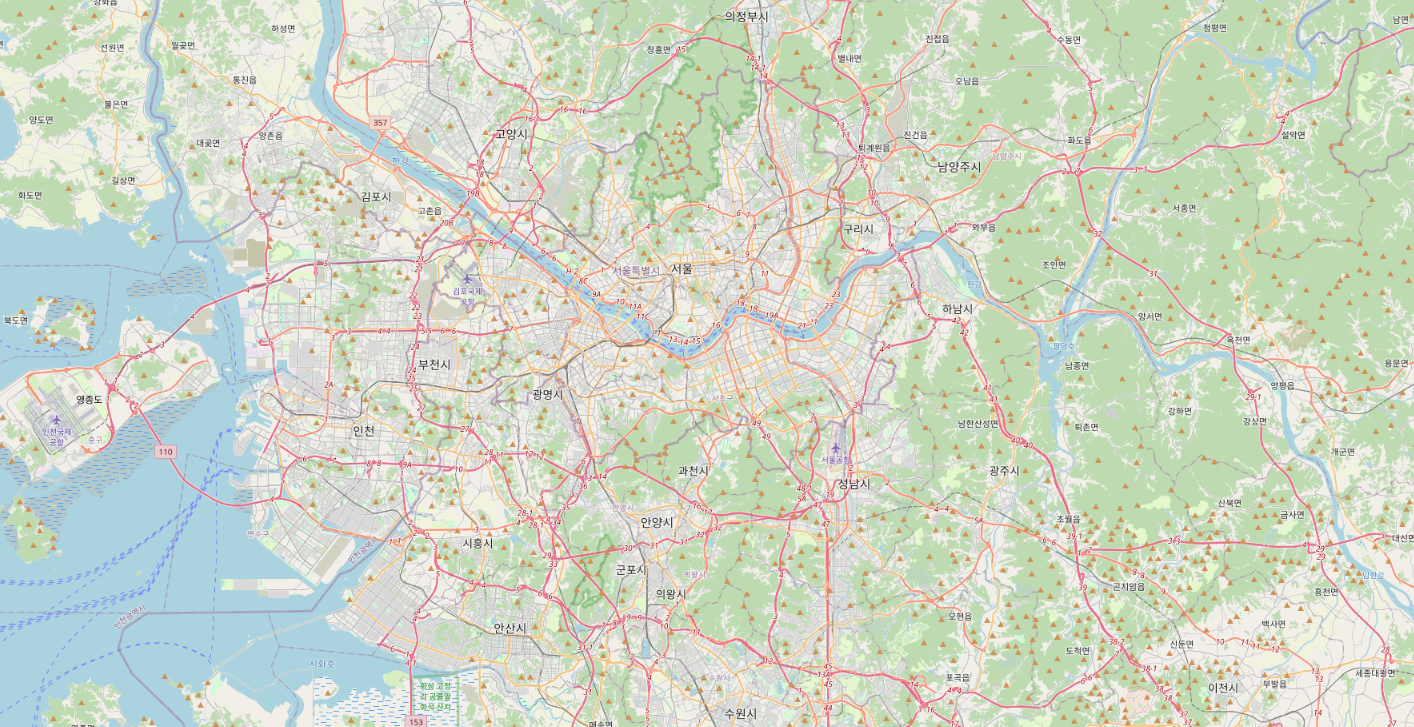
for n in result.index:
radius = result.loc[n,'user_id']
folium.CircleMarker([result['latitude'][n],result['longitude'][n]],
radius = radius/50, fill=True).add_to(m)
m
#
*** 결론 ***
서울 지역에서 수강생의 숫자가 가장 많았고, 다음으로는 대전, 부산 지역 순으로 수강생이 많이 분포
데이터 분석 7강
데이터 분석 종합반 3주차 숙제 제출(https://essay2892.tistory.com/14)




