전처리 & 시각화 3주차
#
#
#
#
#
#
#
#
#
#
#
#
#
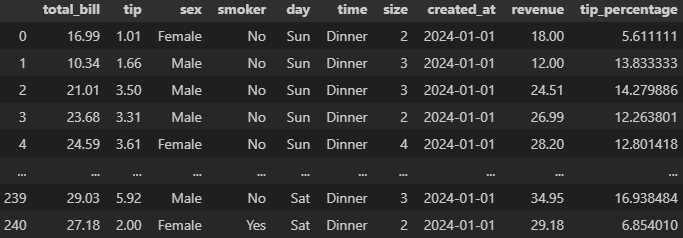
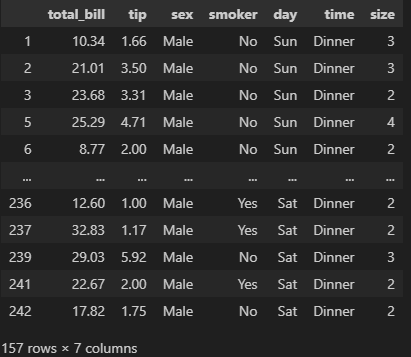
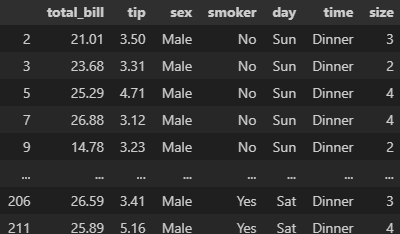
concat() : 데이터프레임을 위아래로 혹은 좌우로 연결
axis: 연결하고자 하는 축(방향)을 지정(기본값 0 - 위아래로 연결). 1로 설정하면 좌우로 연결.
ignore_index: 기본값은 False, 인덱스를 유지. True로 설정하면 새로운 인덱스를 생성.
reset_index(drop=True)도 인덱스 새로 생성
concat([df1, df2, df3 ... ], axis = 0).reset_index(drop = True)
결측치는 NaN으로 나옴
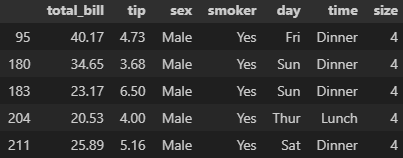
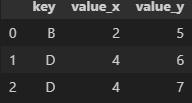
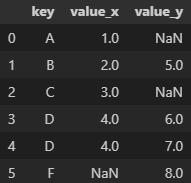
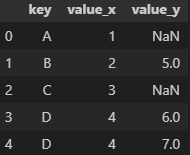
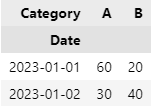
merge() : SQL의 Join과 유사한 기능. 두 개 이상의 데이터프레임에서 공통된 열이나 인덱스를 기준으로 데이터를 병합할 때 활용
데이터프레임의 순서가 중요
on : 기준이 될 컬럼 지정
left_on, right_on: 왼쪽 데이터프레임과 오른쪽 데이터프레임에서 병합할 열 이름이 다른 경우에 사용
how : 병합 방법을 나타내는 매개변수. 기본값은 inner
- 'inner': 공통된 키(열)를 기준으로 교집합
- 'outer': 공통된 키를 기준으로 합집합
- 'left': 왼쪽 데이터프레임의 모든 행을 포함하고 오른쪽 데이터프레임은 공통된 키에 해당하는 행만 포함
- 'right': 오른쪽 데이터프레임의 모든 행을 포함하고 왼쪽 데이터프레임은 공통된 키에 해당하는 행만 포함
#
#
#
#
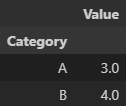
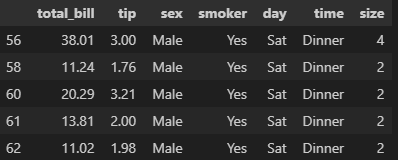
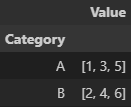
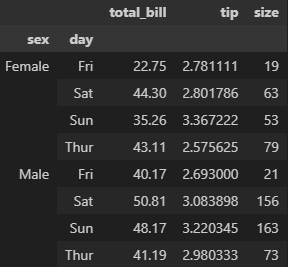
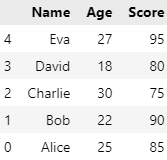
.first()
.min()
.sum() 등등
#
#
#
#
#
#
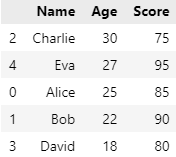
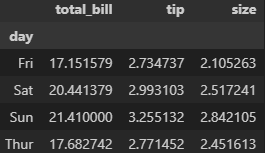
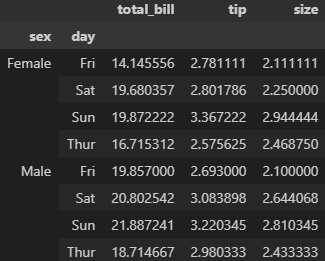
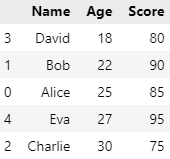
ascending 미작성시 기본값은 오름차순(True)
#
#
pickle : python 의 변수, 함수, 객체를 파일로 저장하고 불러올 수 있는 라이브러리. binary형태로 저장되기 때문에 용량이 매우 작음
#

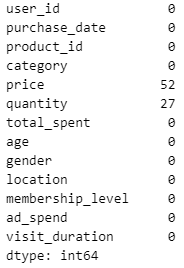
1. user_purchase_data.csv 파일에는 결측치가 포함되어 있습니다. 모든 결측치를 확인하고, 결측치가 있는 행을 제거하세요.
#
#
2. purchase_date 컬럼의 데이터 타입을 문자열에서 datetime으로 변환하고, total_spent 컬럼의 데이터 타입을 정수로 변환하세요.
#


3. 중복된 구매 데이터를 확인하고 제거하세요. 중복의 기준은 user_id, purchase_date, product_id가 동일한 행으로 합니다.
4. price 컬럼에 이상치가 존재합니다. IQR (Interquartile Range) 방법을 사용하여 이상치를 찾아 제거하세요.
5. total_spent 컬럼을 Min-Max 정규화를 사용하여 0과 1 사이의 값으로 변환하세요.
3, 4, 5번은 아직 모르는 내용
4주차 강의까지 듣고 재도전
3주차 실습
데이터 홀로서기
데이터 전처리 문제
내일 다 풀기
'TIL(Today I Learned)' 카테고리의 다른 글
| [2025/01/03]내일배움캠프 QA/QC 1기 - 13일차 (0) | 2025.01.03 |
|---|---|
| [2025/01/02]내일배움캠프 QA/QC 1기 - 12일차 (0) | 2025.01.02 |
| [2024/12/31]내일배움캠프 QA/QC 1기 - 11일차 (0) | 2024.12.31 |
| [2024/12/30]내일배움캠프 QA/QC 1기 - 10일차 (0) | 2024.12.30 |
| [2024/12/27]내일배움캠프 QA/QC 1기 - 9일차 (4) | 2024.12.27 |