프로젝트 명 : 도금욕 변수 예측 모델 구축
주제 : 도금욕 공정에서 수집된 데이터를 분석하여 공정 변수 간의 관계를 파악하고, 특정 변수를 예측하는 머신러닝 모델을 구축하여 공정 최적화
요약 : 날짜별, 로트별로 데이터를 나누어 각 변수간 t-검정, ANOVA검정과 히트맵 시각화를 통해 상관관계 분석 후 공정 변수 예측을 위한 회귀 모델 개발
가설 1. 각 변수는 불량과 밀접한 관계가 있을 것이다.
데이터 확인

상관관계 분석

t검정

가설 2. 날씨(습도)가 불량에 영향을 미칠 것이다.
본래의 데이터만으로는 불량을 판별하기 어렵다 판단하여 외부 데이터를 사용하기로 결정
해당 데이터를 수집한 공장과 인접한 위치에 울산공항 기상대, 울산 기상대가 있어 데이터를 가져오고 교차검증을 진행
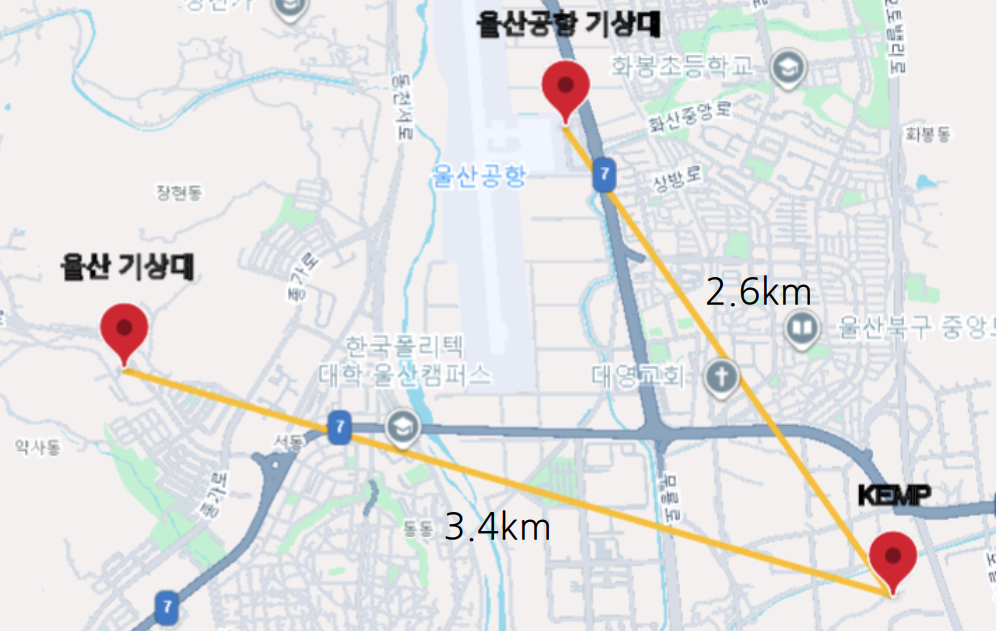

공항은 활주로 운영을 고려하여 기상 영향이 적은 곳에 위치하는 경우가 많기 때문에 주변 산업단지나 도금 공정이 이루어지는 지역의 미세한 기후 변화를 반영하지 못할 것이라 판단되어 울산 기상대의 습도 데이터를 사용하기로 결정.
새로운 데이터 프레임 형성

상관관계 분석

의사 결정 나무

에러(1)을 잘 잡아내지 못하며, 습도 데이터만으로 가지가 나뉘어져 과적합이 일어났다고 판단, 다른 모델을 사용해보기로 결정
랜덤 포레스트


총 데이터 약 50000개 중 오류 데이터는 900개 가량이었으므로 불량과 양품의 데이터 불균형이 큼. Smote를 사용하고 Train-Test-Split을 진행(Split 후 Smote를 진행했어야 했으나 이때는 알지 못했음)
결과적으로 습도가 불량에 영향을 미치는 것으로 보이나 직접적인 영향으로 생각하기는 어려우며, 과적합이 일어났을 것이라 판단됨.
가설 3. 각 변수별로 불량을 발생시키는 특정 수치가 있을 것이다.
하나의 로트 공정(69개 데이터)를 하나의 공정으로 보고 시계열로 나누어 파악하기 위해 데이터를 15초, 115초 단위로 나누어 데이터를 확인하였으나, 불량 예측을 하나도 하지 못함
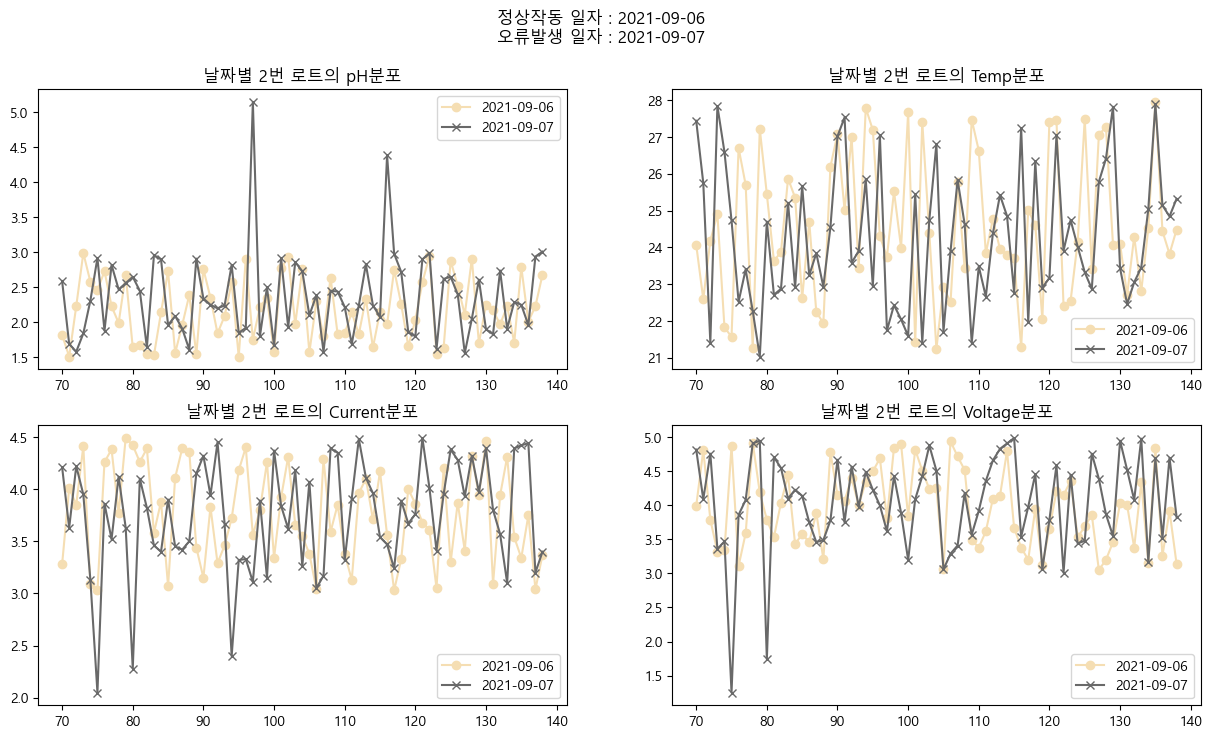
불량 데이터(예: 9/7 Lot 2)를 분석한 결과, 일부 튀는 값(pH, Temp, Current, Voltage)이 존재하지만 대부분의 값은 양품과 비슷함.
1개의 로트당 69개의 측정값 × 4개 변수(총 274개 값)에서 일부 값만 튀는 현상이 보임.
해결책: 데이터 전체를 더 세밀히 분석하고, 새로운 기준으로 재구성 필요
튀어나온 데이터 개수가 많을 경우 불량 발생 가능성이 있음.
이를 바탕으로 불량 발생 원인을 특정하는 기준 설정함.
pH: 3 초과
온도(Temp): 20도 미만
전류(Current): 3 미만
전압(Voltage): 3 미만
이를 특정치로 정의하고 데이터 분류를 진행함.
특정치에 해당 되면 count 가 1회 올라가도록 설정, Count_sum 을 통해 특정 기준치가 몇 번 발생했는지 집계


불량과 양품의 특정 수치를 넘어간 값의 개수 평균 비교 결과 차이가 유의미하다는 점을 확인.
로트가 Error로 판정되어도 그 속에 있는 모든 데이터가 불량인 것은 아님.
pH, Temp, Current, Voltage의 특정치 값의 반복 횟수가 많아질수록 불량일 확률이 높아짐을 확인.
가설 4. 변수별 특정 수치의 반복 횟수는 불량과 관계가 있을 것이다.
기존 데이터 분석에서 개별 측정값이 양품과 유사한 경우가 많아 불량을 명확히 판별하기 어려웠음.

가설 3에서 확인 했듯이, 일정한 범위를 벗어나는 값이 특정 구간에서 반복적으로 발생한다면, 이는 불량과 연관이 있을 가능성이 높음.
단순히 개별 값이 튀는 것이 아니라 제품 생산 시 특정치가 여러번 반복되는지에 초점을 맞출 필요가 있음.
특정 변수(pH, 온도, 전류, 전압)에서 기준을 벗어나는 값의 합계로 불량 예측 모델 생성 단순히 한두번 튀는 값이 아니라, 여러 번 반복적으로 나타날 때 불량과 관련성이 높아지는 경향을 보임.
즉, 불량 제품은 특정 변수의 이상값 발생 횟수가 많고, 정상 제품은 거의 발생하지 않음.
현재 데이터는 5초 간격으로 69번의 측정값이 존재하는 시계열 데이터
불량 여부는 제품 단위(로트 번호 기준)로 결정되므로, 개별 측정값을 그대로 사용하면 데이터가 왜곡될 가능성이 큼
따라서, 각 제품(로트) 단위로 데이터를 집계하는 방식이 필요
69개의 데이터를 1개로 요약하여, 모델이 제품 단위로 판단할 수 있도록 데이터를 변환
1개의 로트 내 69개의 데이터를 묶은 평균값, 표준편차, 최대/최소값, Count_sum, z-score

불량데이터의 불균형 문제를 해결하기 위해 Train-Test-Split 이후 Borderline Smote를 활용
선형회귀

선형회귀 사용시 결정계수(R^2)값이 음수가 나오기 때문에 선형회귀는 사용이 불가능하다 판단
의사결정 나무

AdaBoost


GradientBoost


LGBM


랜덤 포레스트


XGB


이 중 랜덤 포레스트와 XGB 모델을 선택하고 후진 제거법을 활용하여 변수의 수를 줄이기로 결정


이후 모델 성능을 높이기 위해 하이퍼 파라미터 튜닝(Grid Search)을 진행하고 앙상블 모델을 사용




앙상블

추가적인 성능 향상은 보이지 않음.
결론
가설 1 바탕으로 어느 정도 변수들이 불량에 영향이 있는 것으로 판단
가설 2 바탕으로 불량이 습도의 영향을 받는 것으로 보아, 해당 데이터는 1차 공정 혹은 2차 공정에서 수집한 자료로 예측
가설 3 바탕으로 특정치를 구분함. 해당 특정치는 INNOZINC 아연 도금 공정의 수치를 고려하여 설정
가설 4 바탕으로 불량 횟수, pH, Current 가 불량에 직접적인 영향을 미치는 것으로 판단함.
이에 따라 수집 된 50,094 전체 데이터의 pH, Current 값의 평균을 계산해보니, 2차 공정과정 INNOZINC 아연 도금 공정의 표준 수치와 동일함.
데이터의 평균 값 = (pH : 2.29 , Current : 3.73) / INNOZINC 표준치(랙도금) = (pH : 1.5~2.5 , Current : 2.0~5.0)



'QAQC 부트캠프 퀘스트' 카테고리의 다른 글
| [2025/01/24]~[2025/02/03]통계학/머신러닝 개인과제 (0) | 2025.01.31 |
|---|---|
| [2025/01/08 ~ 2025/01/14]기초 프로젝트 - 친환경 차량 성능 데이터 분석 (0) | 2025.01.14 |
| [2025/01/03]Library 개인 과제 (1) | 2025.01.03 |
| [2024/12/31]전처리/시각화 세션 1회차 숙제 (0) | 2024.12.31 |
| [2024/12/26]Python 개인 과제 (0) | 2024.12.26 |