🔩 Level. 1 : 데이터 전처리
더보기
문제 1-1 : CSV 파일 읽기 및 데이터 기본 확인
- CSV 파일을 읽어 DataFrame(df) 을 생성합니다.
- 데이터셋 미리보기 : df의 상위 5개 행을 출력하세요.
- 데이터 정보 : 컬럼명, 데이터 타입, 결측치 등 기본 정보를 출력하세요.
- 기술 통계 : 평균, 표준편차, 최소/최대값 등 기술 통계를 출력하세요.
- 결측값 개수 : 각 열별로 결측값이 몇 개인지 출력하세요.
- 중복 행이 몇 개인지 출력하세요
import pandas as pd
# 1) CSV 파일을 읽어 DataFrame 생성 (Data는 manu)
manu = pd.read_csv('manufacturing_data_400.csv')
# 2) df의 상위 5개 행을 확인하고 출력
manu.head()
# 3) df의 기본 정보(컬럼명, 데이터 타입, etc.) 출력
manu.info()
# 4) df의 기술 통계(평균, 표준편차 등) 출력
manu.describe()
# 5) df의 컬럼별 결측값 개수 출력
manu.isnull().sum()
# 6) df의 중복 행이 몇 개인지 출력
manu.duplicated().sum()
문제 1-2 : 결측치 처리
요구사항
- Defects 열에 이상치로 추정되는 9999라는 값을 발견했습니다.
- Temperature 열에 존재하는 결측치(또는 NaN)을 Temperature 열의 평균값으로 대체
# 1) Defects 열에서 9999 -> NaN으로 대체
import numpy as np
manu['Defects'] = manu['Defects'].replace(9999, np.nan)
# 2) Temperature 열 결측치를 해당 열의 평균값으로 대체
avg_T = manu['Temperature'].mean()
manu['Temperature'].fillna(value = avg_T, inplace = True)
문제 1-3 : 이상치 식별 (IQR)
요구사항
- 사분위수 계산
- Defects 열의 25% 사분위수(Q1)와 75% 사분위수(Q3)를 구합니다.
- IQR(Interquartile Range) = Q3 - Q1 을 계산합니다.
- Lower Bound = Q1 - (1.5 × IQR), Upper Bound = Q3 + (1.5 × IQR)을 계산합니다.
- 이상치 데이터 추출
- Defects 값이 Lower Bound 미만이거나 Upper Bound 초과인 경우를 이상치로 간주하고, 이상치 데이터를 추출합니다.
- 이상치에 해당하는 행이 몇 개인지, 그리고 그 샘플을 출력하세요.
import pandas as pd
import numpy as np
# 1) 사분위수(Q1, Q3) 계산
q1 = manu['Defects'].quantile(0.25)
q3 = manu['Defects'].quantile(0.75)
iqr = q3 - q1
lower_bound = manu['Defects'] < q1 - 1.5 * iqr
upper_bound = manu['Defects'] > q3 + 1.5 * iqr
# 2) 이상치 데이터 추출
outliers = manu[upper_bound | lower_bound]
print("Outliers Count:", len(outliers))
print("Outlier Samples:\n", outliers.head())
# 앞선 결측치 처리 문제에서 이상치를 모두 NaN으로 만들어버려 0이 나오는듯?
#
Outliers Count: 0
Outlier Samples:
Empty DataFrame
Columns: [Date, Line, Production, Defects, Temperature]
Index: []
🔩 Level. 2 : 데이터 시각화
더보기
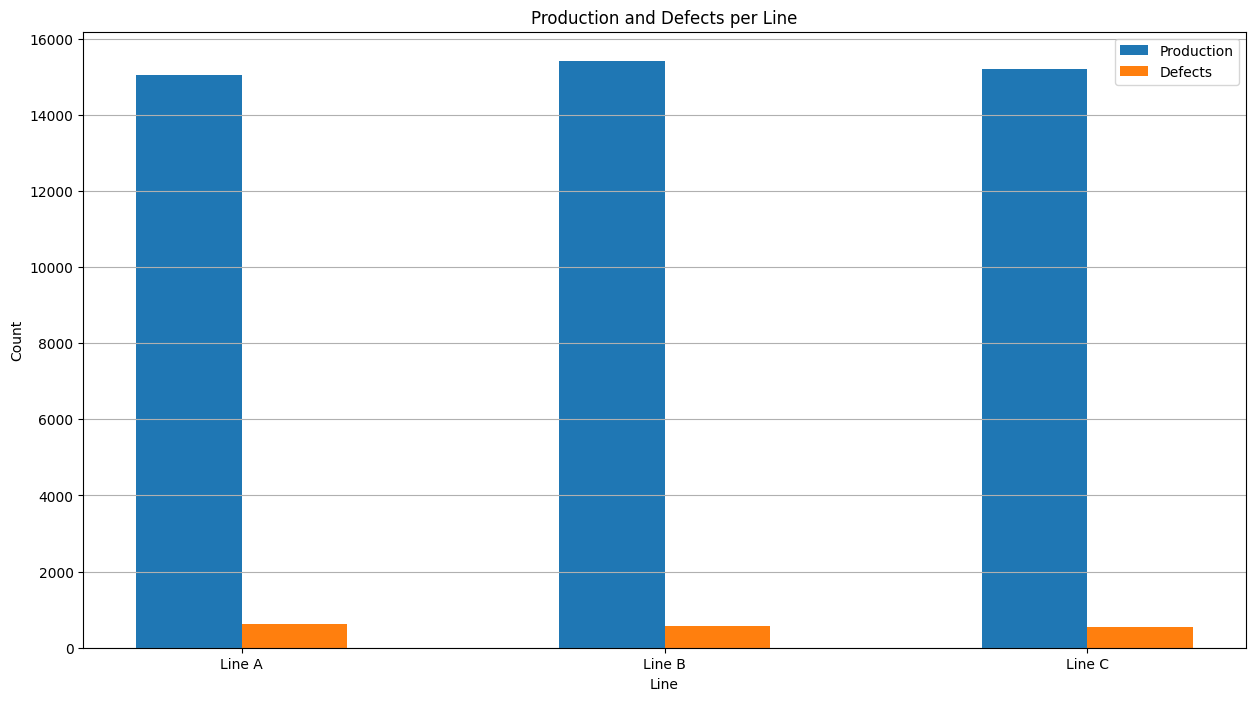
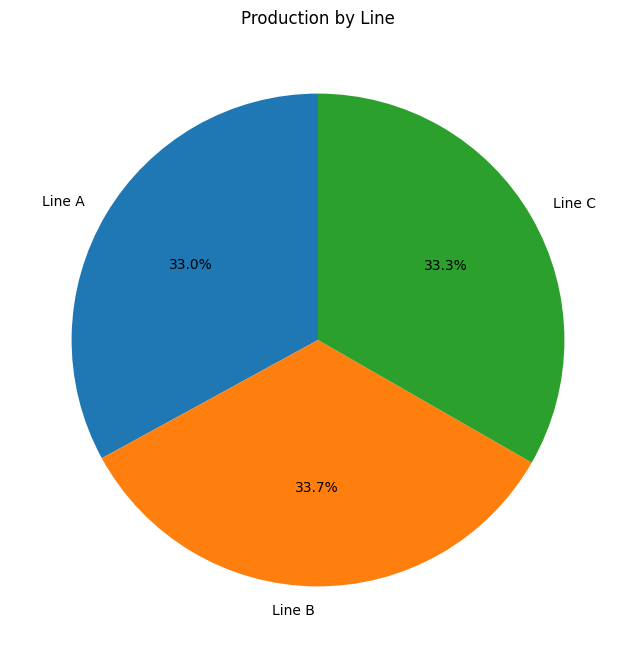
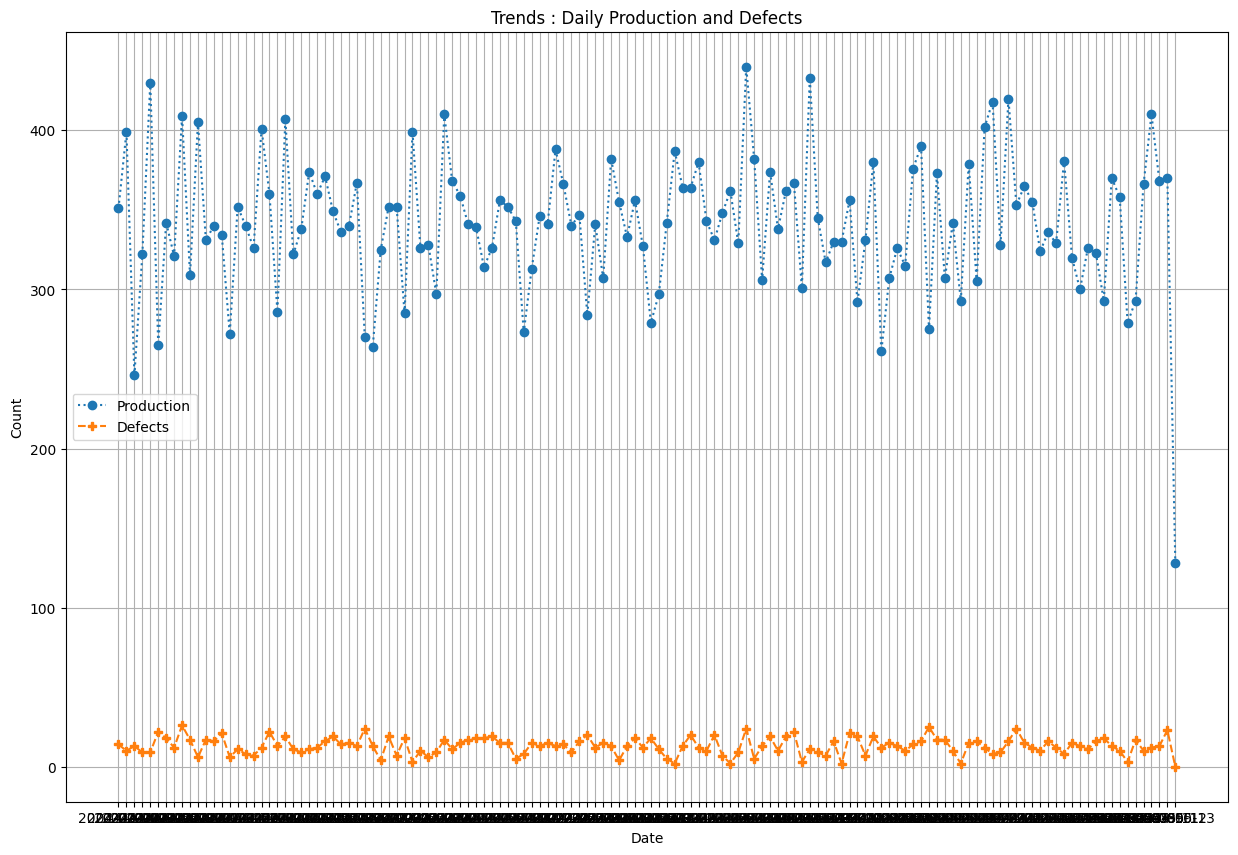
문제 2-1 : Bar Chart : 라인별 Production & Defects
문제 설명
공장 내에는 A, B, C 등 여러 생산 라인(Line) 이 존재하며, 각 라인마다 하루 생산량(Production) 과 불량(Defects) 데이터가 기록됩니다. 라인별로 이러한 데이터를 그룹화하여 생산량과 불량 수치 를 파악하고, 막대 그래프(Bar Chart) 로 시각화하여 비교하려고 합니다.
요구사항
- 라인별 그룹화
- 주어진 데이터에서 라인(Line) 을 기준으로 그룹화하세요.
- 각 라인별 생산량(Production) 과 불량(Defects) 의 총합(합계)을 구하세요.
- Bar Chart 작성
- X축에는 라인(Line) 을 표시합니다.
- Y축에는 생산량(Production) 과 불량(Defects) 의 합계를 나타냅니다.
- 각 라인별로 두 가지 막대(Production/Defects)를 나란히 배치하여 시각적인 비교가 가능하도록 합니다.
- 그래프 꾸미기
- 그래프의 제목(title) 을 적절히 설정하세요.
- X축 라벨(xlabel)과 Y축 라벨(ylabel)을 알맞게 설정합니다.
- 범례(legend)를 추가하여 Production 와 Defects 를 명확하게 구분하세요.
- X축에 라인(A, B, C) 이름이 정확히 표시되도록 하세요 (필요에 따라 plt.xticks 등을 사용)
- Y축에 대한 격자(grid)를 추가하여 막대의 높이를 쉽게 확인할 수 있도록 합니다.
#코드를 작성하세요
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15,8))
index = np.arange(3)
grouped_production = manu.groupby('Line')['Production'].sum()
grouped_defects = manu.groupby('Line')['Defects'].sum()
plt.bar(index - 0.125, grouped_production, width = 0.25)
plt.bar(index + 0.125, grouped_defects, width = 0.25)
#빈칸을 작성하세요
plt.title('Production and Defects per Line')
plt.xlabel('Line')
plt.ylabel('Count')
plt.xticks(index, ['Line A', 'Line B', 'Line C'],rotation=0)
plt.legend(['Production', 'Defects'])
plt.grid(axis='y')
plt.show()
#
문제 2-2 : Pie Chart: 라인별 Production 비중
문제 설명
공장 내 여러 생산 라인(A, B, C)이 전체 생산량(Production)에서 각각 어느 정도의 비중을 차지하는지 파악하기 위해, 파이 차트(Pie Chart) 를 작성하려고 합니다.
요구사항
- Pie Chart 작성
- 파이 차트를 사용하여 각 라인의 Production 비중을 시각화하세요.
- 각 파이 조각에 라인 이름과 퍼센트(%) 를 표시하기 위해 autopct='%1.1f%%' 옵션을 사용하세요.
- 파이 차트의 색상을 라인별로 다르게 지정하여 구분이 용이하도록 합니다.
- 그래프 꾸미기
- 그래프의 제목(title) 을 적절히 설정하세요 (예: "라인별 Production 비중").
- 불필요한 축 라벨(예: 축 눈금)을 제거하여 파이 차트가 깔끔하게 보이도록 합니다.
- 그래프의 색상을 명확히 구분할 수 있도록 설정하세요.
#코드를 작성하세요
plt.figure(figsize = (8, 8))
plt.pie(grouped_production, autopct = '%1.1f%%', labels = ['Line A', 'Line B', 'Line C'], startangle= 90)
plt.title('Production by Line')
plt.show()
#
문제 2-3 : 혼합 Line Chart: 일자별 Production & Defects
문제 설명
공장에서는 매일 다양한 제품을 생산하고, 그 과정에서 발생하는 불량 수량 역시 기록합니다. 일자별 생산량(Production)과 불량 수량(Defects) 을 시각적으로 비교하여 불량률 추이와 생산 변동성을 파악하려고 합니다. 이에 따라, 주어진 데이터를 날짜별로 집계하고 선 그래프(Line Chart) 로 나타내는 작업을 수행해야 합니다.
요구사항
- 날짜별 집계
- 주어진 데이터에서 “일자(Date)”, “생산량(Production)”, “불량(Defects)”을 날짜별로 그룹화하여 총합(또는 평균)으로 집계하세요.
- Line Chart 작성
- X축에는 날짜(Date)를, Y축에는 “생산량(Production)”과 “불량(Defects)” 수치를 배치합니다.
- 날짜별 “Production”을 나타내는 선과 “Defects”를 나타내는 선을 같은 그래프에 그립니다.
- 그래프 꾸미기
- 그래프의 제목(title) 을 적절히 설정하세요.
- X축 라벨(xlabel)과 Y축 라벨(ylabel)을 설정합니다.
- 범례(legend)를 통해 두 선이 어떤 값(Production/Defects)인지 명확히 구분되도록 합니다.
- 그래프에 격자(grid)를 추가하여 가독성을 높이세요.
# 1) 날짜별 집계
grouped_data = manu.groupby('Date')[['Production', 'Defects']].sum()
# 2) 선 그래프(Line Chart) 작성
plt.figure(figsize=(15,10))
plt.plot(manu['Date'].unique(), grouped_data['Production'], linestyle = ':', marker = 'o',label='Production')
plt.plot(manu['Date'].unique(), grouped_data['Defects'], linestyle = '--', marker = 'P',label='Defects')
plt.title('Trends : Daily Production and Defects')
plt.xlabel('Date')
plt.ylabel('Count')
plt.legend(loc = 6)
plt.grid()
plt.show()
#
🔩 Level. 3 : 도전! 한 걸음 더 나아가기
더보기
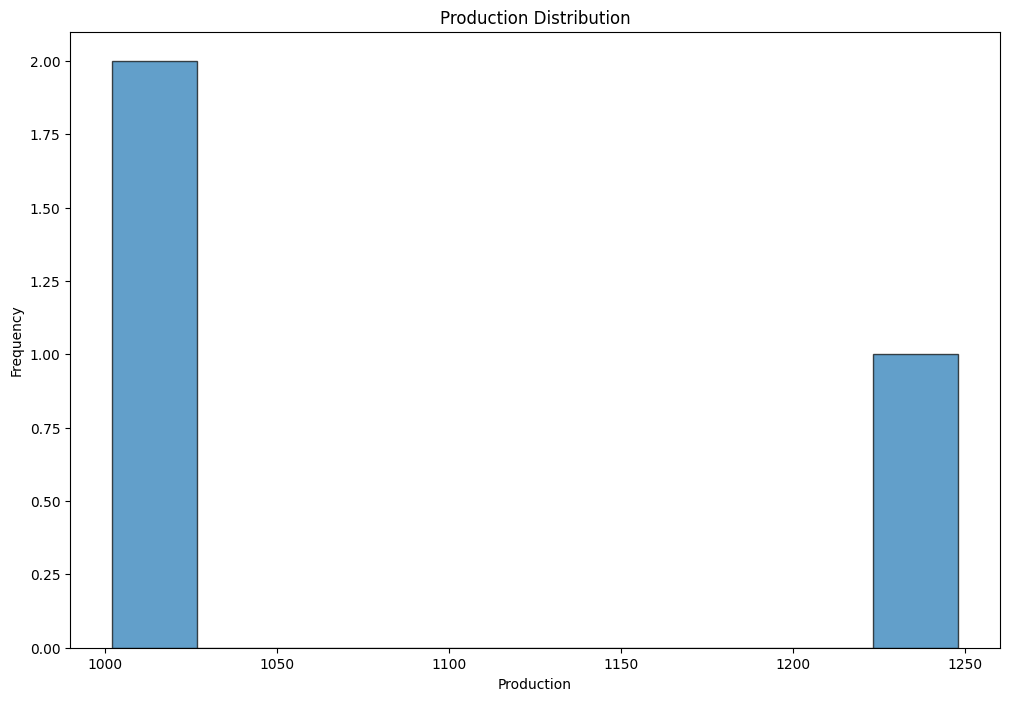
문제 3-1 : Production distribution
요구사항
- data_cleaned라는 DataFrame에서 production 열을 사용하여 히스토그램을 작성하세요.
- 그래프는 2행 3열(subplot(2, 3, 1)) 레이아웃에서 첫 번째 위치에 표시되도록 설정하세요.
- 막대(bin)의 개수(bins)는 10으로, 막대 테두리 색(edgecolor)은 'k'(검정색), 투명도(alpha)는 0.7로 지정하세요.
- 그래프 제목(title)은 'Production Distribution'으로 하고,
- x축 라벨: 'Production'
- y축 라벨: 'Frequency'를 각각 설정하세요.
- 히스토그램이 완성되면, 생산량이 어떤 구간대에 집중되어 있는지 간단히 해석해 보세요. (예: “생산량이 대체로 20~40 구간에 몰려 있다.” 등)
df = pd.read_csv('data_with_duplicates.csv')
data_cleaned = df.drop_duplicates().dropna()
data_cleaned
# 라이브러리 불러오기
import matplotlib.pyplot as plt
import pandas as pd
# 히스토그램 생성
plt.figure(figsize = (12, 8))
plt.hist(data_cleaned['production'], bins = 10, edgecolor = 'k', alpha = 0.7)
# 제목 및 축 라벨 설정
plt.xlabel('Production')
plt.ylabel('Frequency')
plt.title('Production Distribution')
# 그래프 표시
plt.show()
# 생산량이 1000~1020 구간에 몰려있는 것처럼 보이지만, 데이터의 양이 너무 적어 판단하기 어렵다.
#
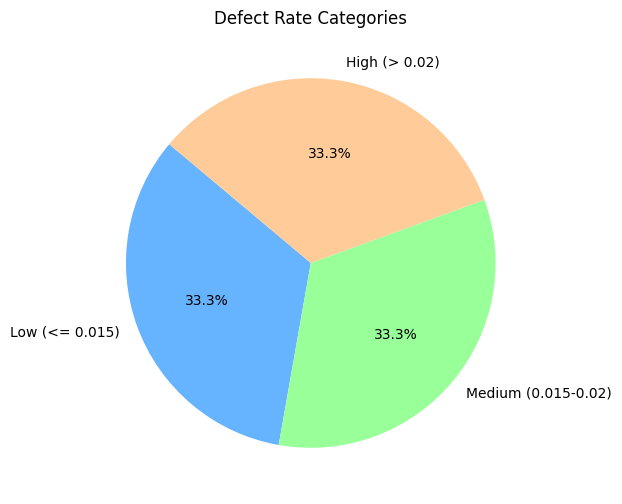
문제 3-2 : Defect Rate Category 파이 차트 시각화
요구사항
- 결함률(defect_rate) 데이터를 구간(binning) 별로 범주화(Category)하십시오.
- 구간 구분은 [0, 0.015, 0.02, 0.025]로 설정하고, 각 구간에 대한 범주 라벨(labels)은 ['Low (<= 0.015)', 'Medium (0.015-0.02)', 'High (> 0.02)']로 지정하세요.
- pandas.cut() 함수를 활용하여, data_cleaned['defect_rate']를 defect_rate_category라는 새로운 컬럼으로 생성하세요.
- 범주화된 결함률(defect_rate_category)의 각 범주별 빈도수를 계산하세요. (value_counts() 활용)
- 파이 차트(Pie Chart)를 그릴 때, 아래 조건을 만족하세요.
- 차트 크기: figsize=(8, 6)
- 파이 섹션의 색상: ['#66b3ff', '#99ff99', '#ffcc99']
- 퍼센트 표시: autopct='%1.1f%%'
- 시작 각도: startangle=140
- 차트 제목: 'Defect Rate Categories'
- 파이 차트를 통해, 결함률이 어느 구간에 많이 분포되어 있는지 확인하고, 그에 대한 짧은 해석을 기술하세요.
- 예: “대부분의 결함률이 Low (<= 0.015) 구간에 분포한다.”, “약 20%는 High (> 0.02) 범주에 해당한다.” 등
# 라이브러리 불러오기
import matplotlib.pyplot as plt
import pandas as pd
# 구간(binning)과 라벨 설정
defect_rate_category = pd.cut(data_cleaned['defect_rate'], bins = [0, 0.015, 0.02, 0.025], labels = ['Low (<= 0.015)', 'Medium (0.015-0.02)', 'High (> 0.02)'])
# 결함률 데이터를 범주화하여 새로운 컬럼 생성
data_cleaned['defect_rate_category'] = defect_rate_category
# 파이 차트 생성
plt.figure(figsize = (8, 6))
plt.pie(data_cleaned['defect_rate_category'].value_counts(),
autopct='%1.1f%%',
startangle=140,
colors = ['#66b3ff', '#99ff99', '#ffcc99'],
labels = ['Low (<= 0.015)', 'Medium (0.015-0.02)', 'High (> 0.02)'])
# 차트 제목 설정
plt.title('Defect Rate Categories')
# 차트 표시
plt.show()
# 분석가의 해석
# 각 범주에서 나타나는 결함률의 빈도수는 동일하게 나타나지만, 데이터의 수가 너무 부족하여 분석이 불가능하다.
#
'QAQC 부트캠프 퀘스트' 카테고리의 다른 글
| [2025/01/24]~[2025/02/03]통계학/머신러닝 개인과제 (0) | 2025.01.31 |
|---|---|
| [2025/01/08 ~ 2025/01/14]기초 프로젝트 - 친환경 차량 성능 데이터 분석 (0) | 2025.01.14 |
| [2024/12/31]전처리/시각화 세션 1회차 숙제 (0) | 2024.12.31 |
| [2024/12/26]Python 개인 과제 (0) | 2024.12.26 |
| [2024/12/20]온보딩 주차 KPT 회고 (0) | 2024.12.20 |